Stability is clearly improved with watchdog values inherited from @Ektus
root@einstein:~# uptime
15:55:04 up 3 days, 5:24, load average: 4.61, 3.44, 3.25
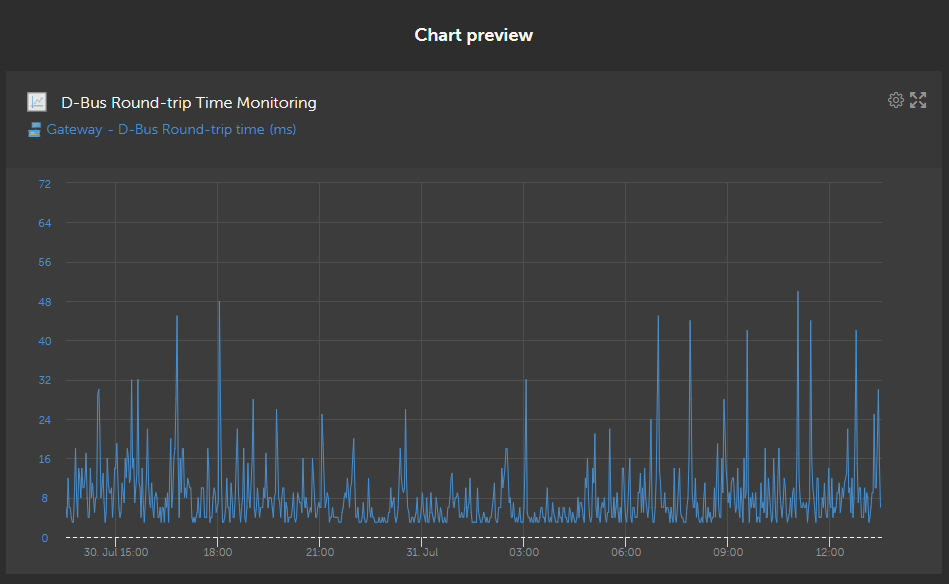
Here ist the diagram of my recent dbus cycle time. I setup the widget without ai manually. The average loads do not show any trace for unknown reasons. Over the night hours, the peaks seems to calm down, why I added other values for correlation.
As this morning was cloudy with rain, I disabled Node Red at 8:20 complety. This location is the 3rd peak from the right with about 50 msec height. At about 3pm another peak with about 85mS is recorded.
Assume all, NodeRed seems to increase occasional peaks only a little but not too much. They are typically around 100msec. With the default watchdog values I saw frequently peaks up to about 500msec probably caused by the reboot process itself. I am going to enable NodeRed again, possibly testing the current regulator with a cycle time down to 1 second for a faster response until the physical grid current limits.
Edit: After changing the poll intervall of the Ziehl EFR @Modbus TCP down to 333 mSec, there was no visibile impact to the CPU load. Therefore I started to examine the “myths and legends of 400W/s”. Image shows shaking of grid by change of grid sepoint between 0,25 and 25kW every 30 seconds.
Next image is same but meassured by ABB meter->Modbus RTU->USB-dbus instead of Ziehl EFR-
Both diagrams are much faster than 400W/s. For both instruments I assumed a significant averaging of the values why I repeated the same experiment with current clamp and scope. The records were done with only one phase of current, no absolute power why I did not save any images from. What the scope shows are 2 seconds absolute delay from writing the value to dbus until anything happens. After this, current goes to end value inside 4 seconds what is more than 6kW/second. Assume the change of process value by any load instead the setpoint value, the regulator probably changes without any delay, at least if grid is offline. This behaviour needs to be examined in another experiment. The reason for 2 seconds delay is unknown. Its annoying if they are inside a external regulators loop what governs the ESS. Any case, they do not contribute anything to system stability. So far, there is no reason to make any NR flows cycle time or Modbus polling shorter for the moment.
Without any meassurements or instruments, the humming sound of the Multis torroid transformer is a good indicator on how the power increases at sudden loads.